
面向对象设计与构造OO:Unit3-社交网络
0 前言
第三单元的内容聚焦在实现简单社交关系的模拟和查询;学习目标为对规格化开发(以入门级 JML 规格为例)的理解与相应的代码实现。本单元最难的部分是选取合适的图算法优化代码的时间复杂度;最重要的思想是契约式编程。
本文将分别介绍分析三次迭代作业,每部分包括需求说明、规格实现、性能优化、测试方案。最后总结心得体会。
1 第九次作业
1.1 需求说明
第一次迭代需要根据输入的指令构建一个社交网络,是一个有权无向图,每个结点都是一个用户,用户有多个好友,同时可以对好友进行标签分类。
1.2 规格实现
1.2.1 UML 类图
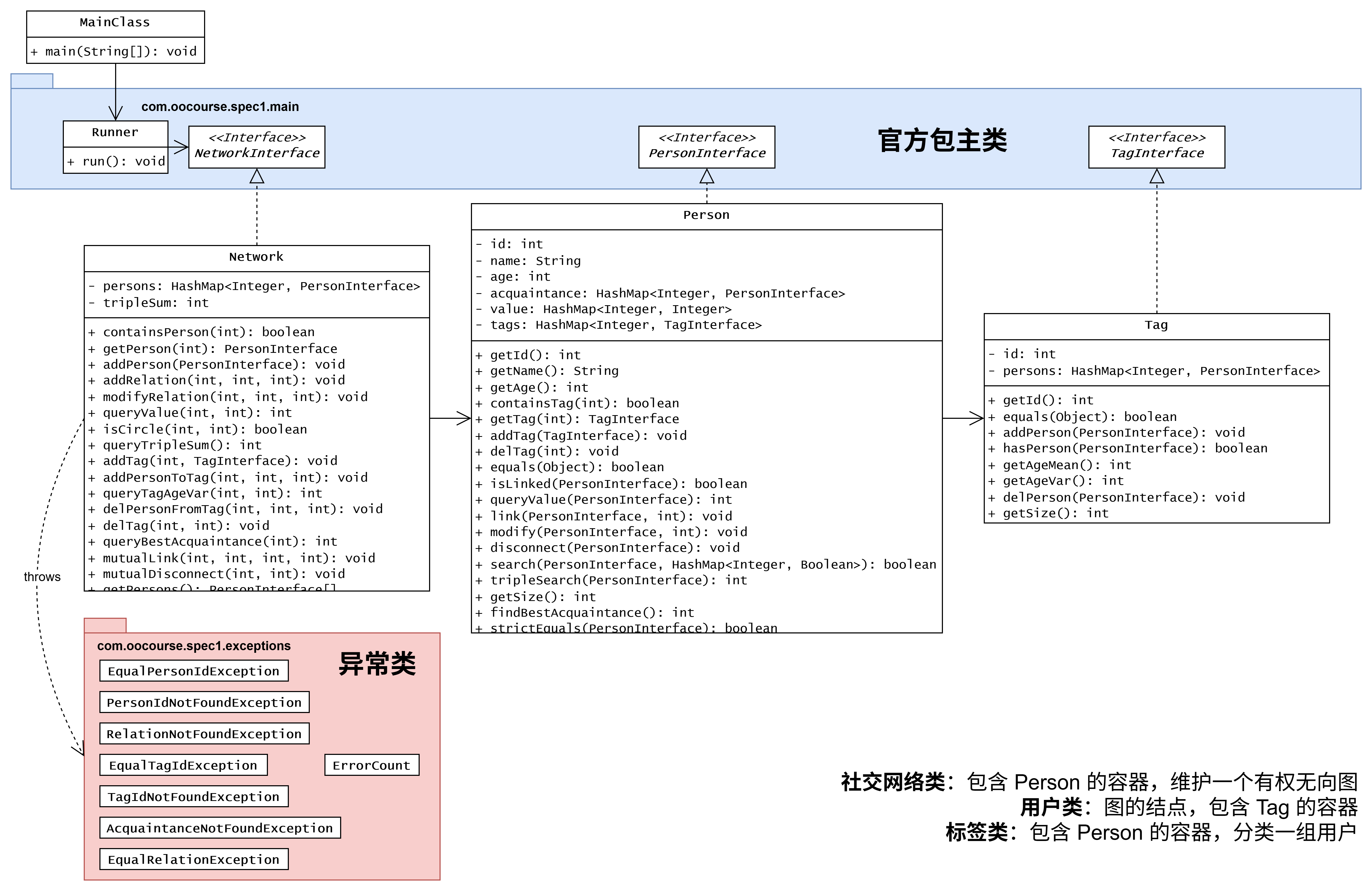
1.2.2 JML 规格实现
本次迭代大部分方法都可以直译 JML,但为了更好的性能和更方便的操作,规格与实现应当有所分离。
1.2.2.1 集合类的选取
JML 并不规定使用什么类型的集合,但通读 JML,发现几乎所有集合由此特点:存储的对象都有一个独一无二的 id。因此,使用 HashMap 构建 id 和 obj 的映射是不二之选,存取复杂度都是 O(1)。
1.2.2.2 JML 的阅读复杂性
JMl 力求精准,因此在可读性上有所欠缺。有如下 JML:
1 | /*@ ensures \result == (persons.length == 0? 0: |
放眼望去全是括号嵌套,Java 注释的灰色将视觉混淆,本是求均值明白先加再除,可 JML 的繁杂黯淡了自然语言的精妙。
笔者没注意括号匹配,实现过程中误将 (a + b + c) / n 的操作写成 (a / n) + (b / n) + (c / n) ,向下取整的无形大手发力,你在强测中获得了 0 分。
1.2.2.3 优雅地抛出异常
刚开始写的时候先入为主地写了“if 没有异常, else if 有异常”的结构,但发现“没有异常”其实就是“有异常”的取反并集,不如写成“if 有异常, else if 有别的异常……else (没有异常)”的结果。赏心悦目。
1.3 性能优化
1.3.1 寻找三元环
public int queryTripleSum(),如果直接按照 JML 实现需要遍历网络中的所有 person,每个用户遍历他对应的 acquaintance,接着遍历 acquaintance 的 acquaintance,再遍历 acquaintance 的 acquaintance 的 acquaintance,三个循环嵌套,O(n^3) 的复杂度无穷匮也!
并查集算法学习成本高,笔者直接无脑增量维护效果拔群 (^_^)。
简单来说,每次增加或删除一条边,判断一下存着的 tripleSum 变量是否更改。那么什么时候需要更改呢?即更改关系的两个人 a 和 b,如果他俩可以通过且仅通过 1 个人进行联络,则认定是在“破坏一个三元环” or “构建一个三元环”。经过分析三元环之间是独立的,不会出现矛盾,具体代码如下:
1 | // search for how many "this->mid->person" |
1.4 测试方案
1.4.1 Junit 单元测试
本次迭代需要编写针对 queryTripleSum 方法的单元测试。
尝试了随机数据生成以及构造特殊数据,但前者效果并不好,因为数据密度不大。对于构造特殊数据,即空图、一边、三元环、四元环、四元完全图等依次测试,不到六元就能通过 Junit 测试。
此外还需要注意方法的 pure 性,即使用方法前后不能对 network 的属性进行更改,需要保持不变。测试这个部分,我在最开始就创建了两个独立的网络 network 和 oldNetwork,并且对它们同步进行 addPerson 和 addRelation 操作,最后只对一个进行 qts 操作,然后判断各自内部属性是否 strictEquals 即可。
1.4.2 评测机搭建
这里先回答一下博客要求的第一个问题!
- 单元测试:针对软件中的最小可测试单元进行的测试,,旨在验证单个单元(通常是函数、方法或类)的功能是否按照预期工作,并尽可能地覆盖不同的代码路径和边界情况。
- 功能测试:通过模拟用户操作来验证系统功能是否符合需求和规格说明,需要尽可能覆盖整个系统的功能,验证系统的输入与输出是否符合预期。
- 集成测试:验证不同模块之间的交互和集成是否正常工作的测试过程,将已经通过单元测试的模块组装成完整的系统,并进行接口测试、模块间通信测试等,以确保模块之间的集成没有问题。
- 压力测试:评估系统在负载较大或极端条件下的性能表现的测试方法,通过模拟大量用户访问、高并发操作等情况,来测试系统的稳定性、可靠性和性能表现。
- 回归测试:在软件发生变更后重新运行之前的测试用例,验证软件的修改是否对现有功能产生了影响,以确保修改没有引入新的错误或破坏现有的功能。
我的评测机采用随机数据生成+输出对拍,显然属于功能测试!很可惜这次作业的评测机弱爆了。分析后发现原因如下:
- 图过于稀疏。因为所有
id的数据范围都是int内,倘若真的设置在int内随机生成id,是很难随机出两个同样的id的,也就是说某个操作加了一个用户,但他之后都不会被用到了()。后面缩小范围到了 -150~150 左右,但仍然有些稀疏。 Person、Tag的id尺度相同。这是不对的,因为Person理论上会比Tag多,这样导致在Person的尺度视角下,Tag的分布过于稀疏。- 没有实现“根据已有的
id生成数据”或“避开已有的id生成数据”的功能。但这是必要的,例如addPerson的时候期望避开已有的id,而addPersonToTag的时候期望从已有的id中获取。(在异常抛出功能已经测试正确的情况下)
2 第十次作业
2.1 需求说明
在之前的基础上,新增公众号和文章,公众号可以发出文章,用户可以关注公众号、接收文章。
2.2 规格实现
2.2.1 UML 类图
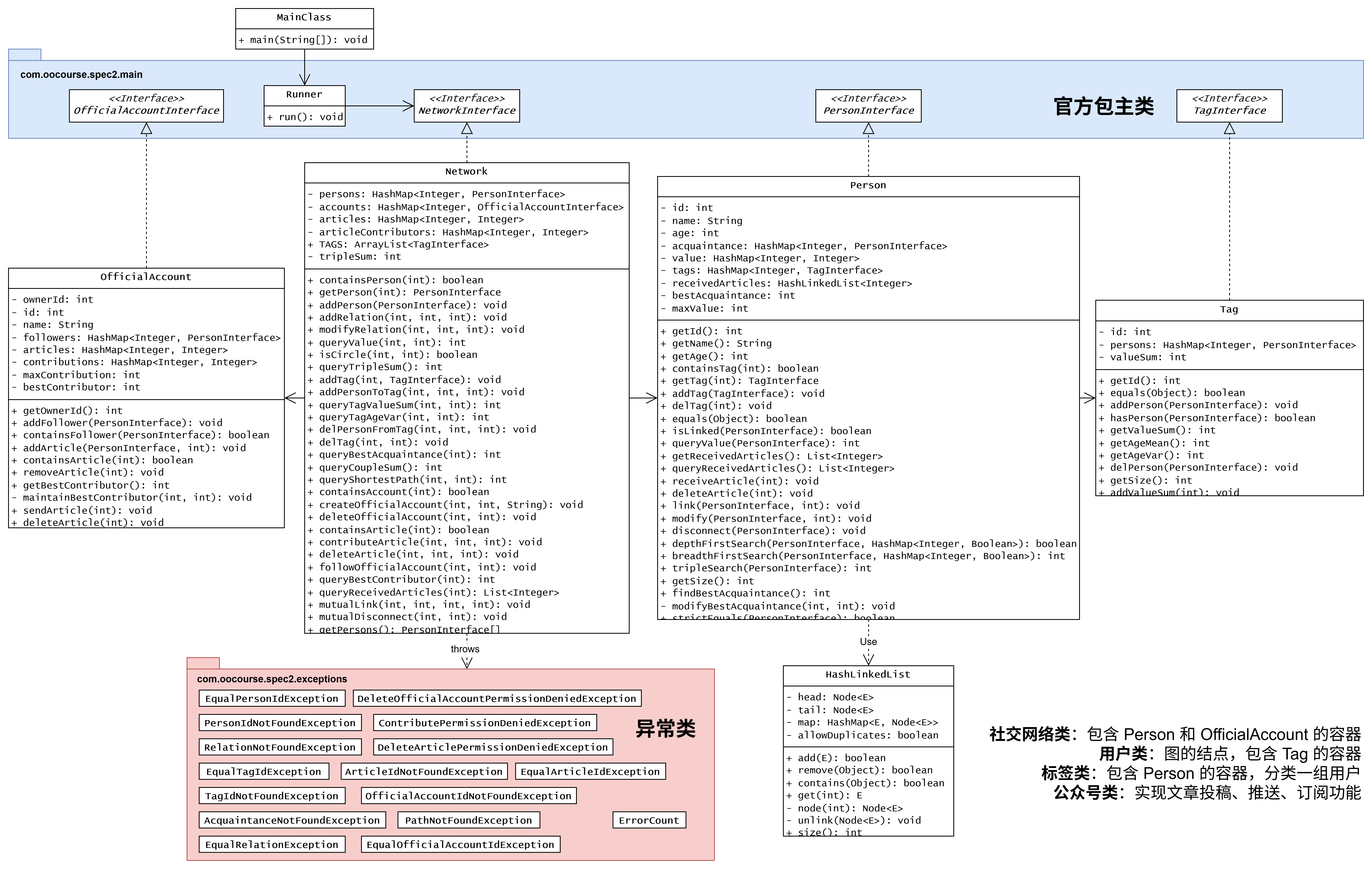
2.2.2 JML 规格实现
没什么好说的。本次作业强测超时一个点,其余全对。具体优化在之后说明。
2.2.3 大模型辅助
2.2.3.1 BFS 算法直接生成
笔者在 hw9 的搜索需求中手写了 DFS 算法,但这次作业中新增的 queryShortestPath 查找最短路径使用 BFS 可以完美解决,无法复用之前代码。为了偷懒高效编程,直接去问 LLM!于是也是准确无误地运行了。
2.2.3.2 优化已有代码
在 queryCoupleSum 方法中,原先 O(n^2) 复杂度的算法担心超时,于是求助 LLM。
Prompt 如下!
这段代码计算了一个无向图中符合“A权值最大的直接连接的结点是B,且B权值最大的直接连接结点是A”的结点对的数目。经过我不完全归纳发现这个结果就是无向图的连通子图的数目(一整块连通的算一个),你能用这种方式优化一下时间复杂度吗
Deepseek 是这么说的:
为了优化时间复杂度,我们可以避免双重循环,转而通过记录每个结点的最佳熟人并线性检查互为最佳的对。以下是优化后的代码:
1 |
|
简单来说,是先循环一次记录一个字典,然后再循环一次计算结果。避免了循环嵌套,用空间换时间。
2.2.3.3 生成期望数据结构
在 receivedArticles 的组织中,笔者原本使用 LinkedList 双向链表,但发现链表取出头部的效果虽好,但查找效果很差。而 HashMap 的查找效果很好,但无法记录顺序。为了不 TLE,笔者想实现一个 HashLinkedList 数据结构,结合二者功能。
然而有些操作涉及偏底层代码实现,交给 LLM 来做了。
2.3 性能优化
主要性能优化在上一条大模型辅助中介绍。
附 HashLinkedList 实现(需要支持重复元素):
1 | public class HashLinkedList<E> extends AbstractList<E> { |
2.4 测试方案
2.4.1 Junit 单元测试
本次作业需要针对 queryCoupleSum 进行单元测试。和之前一样,构造特殊数据并测试 pure 即可通过所有测试点。在构造数据的过程中,归纳发现该结果就是连通子图的数量。也就有了前文提到的优化,给了 LLM 合适的提示词。
2.4.2 评测机搭建
这次的评测机很强!甚至测出了评测机做不出的点。
主要是弥补了上一次作业的三个漏洞:增大密度、个性化尺度、考虑已有 id 信息。
3 第十一次作业
3.1 需求说明
在之前的基础上,完成对消息收发的模拟。消息包括表情消息、转发消息、红包消息。
3.2 规格实现
3.2.1 UML 类图
3.2.2 JML 规格实现
这次作业的消息发送具有很复杂的 JML,让人体会到了自然语言高于 JML 之处。
本次作业也没有需要性能优化的地方。
3.3 测试方案
3.3.1 Junit 单元测试
本次作业需要针对 deleteCodeEmoji 进行单元测试。这次的方法不是 pure 了所以不用测。依旧构造特殊数据,但需要特别测试 messages 容器是否也进行了删除,这是 JML 中做了正确性约束的。
4 心得体会
我觉得 JML 很鸡肋(诚实)。它没有自然语言的可读性和简洁性,唯一的准确性也可能因为可读性太低而丢失。或许它是在 LLM 语境下的不错实践,但 LLM 也可以阅读自然语言啊()。
我觉得本单元更重要的思想是“契约式编程”。无论是 JML,还是需求文档等其他形式,实现高效编程协作(面向对象)的要求是能够没有歧义地限定边界。
在之前的单元中,我会尝试在自己写的方法上加上注释,提示自己“这个方法是在xx基础上进行的”,比如“输入数据已经排好序了”。避免进行重复冗余操作或者因为出现 bug。而 JML 很好地做到了这件事情,requires 就是前提条件,也就是我在注释中尝试限定的东西。
JML 也是为了实现高内聚低耦合的面向对象实践啊!
- Title: 面向对象设计与构造OO:Unit3-社交网络
- Author: BaconToast
- Created at : 2025-11-18 15:17:44
- Updated at : 2025-11-18 15:23:05
- Link: https://bacontoast-pro.github.io/2025/11/18/oo/u3/
- License: This work is licensed under CC BY-NC-SA 4.0.