
编译技术:语法分析
语法分析设计
编码前的设计
需求分析
读取词法分析构建的 TokenList,分析其语法成分并将结果输出至 parser.txt。如果存在错误则将错误信息输出至 error.txt。
文法见“2025编译技术实验文法定义及相关说明.pdf”。
错误类别码见下表。
语法分析错误类型
| 错误类型 | 类别码 | 解释 |
|---|---|---|
| 缺少分号 | i | Stmt, ConstDecl 及 VarDecl 中的 ‘;’ |
| 缺少右小括号 ‘)’ | j | 函数调用 ( UnaryExp )、函数定义 ( FuncDef, MainFuncDef )、Stmt 及 PrimaryExp 中的 ‘)’ |
| 缺少右中括号 ‘]’ | k | 数组定义 ( ConstDef, VarDef, FuncFParam ) 和使用 ( LVal ) 中的 ‘]’ |
文件组织
新建目录 src\frontend\parser,该部分实现语法分析部分的“主函数”。其中包含一个类:
- Parser:该模块“主函数”,定义抽象语法树根节点。
新建目录 src\frontend\ast,该部分定义抽象语法树的所有节点。其中的类过多,主要类为:
- Node:节点类,是所有其他节点的父类,内含 ArrayList 存储其孩子节点。
- SyntaxType:枚举类,枚举所有节点类型。
总体思路
实现带回溯的递归下降子程序法,该法的优点在于强大的面向对象能力,无需人为构建抽象语法树,仅需遵循文法定义。其中有几个实现关键:
- int pointer:指针,每个节点类都有,指向当前读取的 TokenList 的位置。
- boolean fake:作废标记,如果当前节点被认为是错误的,将其作废。
- void save():存档,即记录当前指针,然后进入新的节点中去移动指针。
- void load():读档,即回到上一次存档的地方,这一操作是在作废完成后的回溯操作。
作废-读档机制实现了在树形遍历中寻找唯一成功路径的方法,通过不断试错、递归、回溯最终能够找到答案。因此回溯法是文法添加友好的,不需要大范围修改和对文法进行化简。
编码完成之后的修改
TokenStream 类
新建类 src\frontend\lexer\TokenStream.java,该类实现了指针在 TokenList 中的移动。
TokenNode 类
位于目录 src\frontend\ast,继承于 Node 类,用于定义终结符的节点。
消除左递归
节点类别中多个表达式节点的初始文法定义含有左递归,以 AddExp 为例:
1 | AddExp → MulExp | AddExp ('+' | '−') MulExp |
对 MulExp 作废后,进入第二条分支,此时再次进入 AddExp,将导致无穷递归。因此需要消除左递归:
1 | AddExp → MulExp { ('+' | '−') MulExp } |
下面这条文法虽和上面等价(句子相同)并且可以被回溯法正确处理,但仍存在 bug:构建的语法树结构不同。考虑这样的结构:MulExp + MulExp - MulExp:
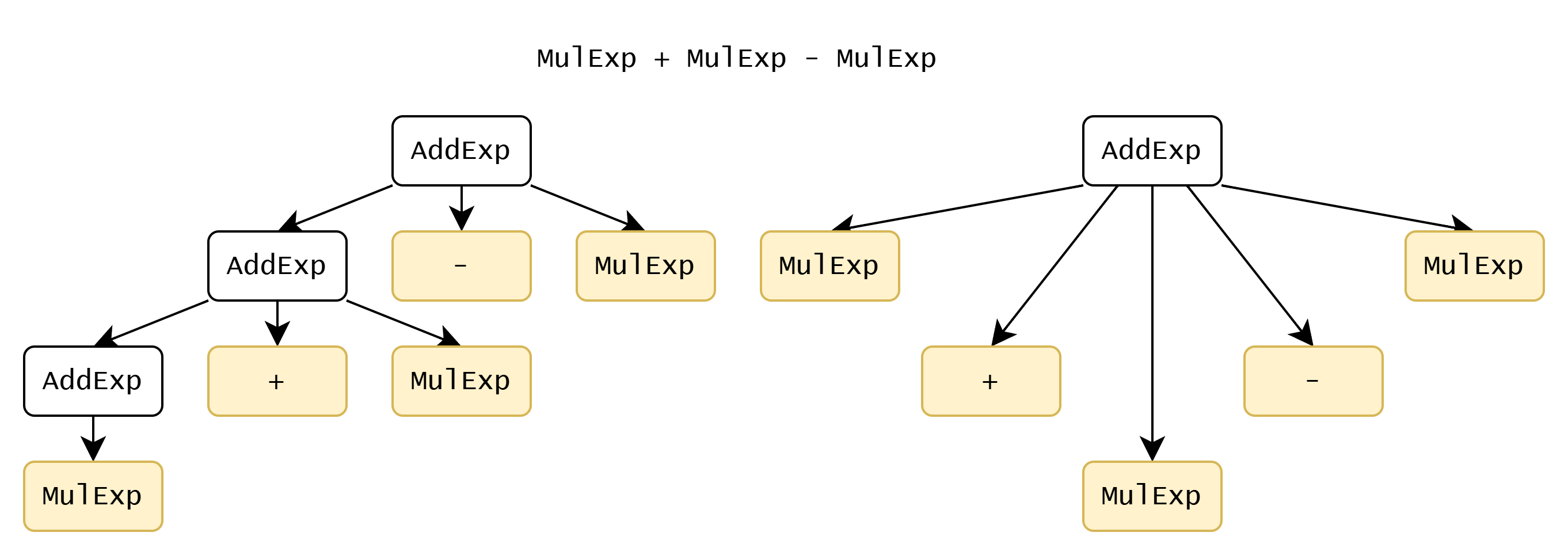
正确文法构建的语法树如左图,化简后的文法构建的语法树如右图。想不到更好的方法,于是人工将右边的树转为左边。
不可避免的预读
回溯法仍然无法避免部分预读,如 Ident 和 Ident[],前者是标识符叶节点,后者是数组,如果提前敲定将会把后面的中括号视为错误。
又如,UnaryExp → PrimaryExp | Ident '(' [FuncRParams] ')' | UnaryOp UnaryExp,其中 PrimaryExp 与 Ident 存在重合,如果提前确定为 PrimaryExp 将会导致后续小括号读取视为错误。
还有,Stmt → LVal '=' Exp ';' | [Exp] ';' | ...,其中 LVal 可能是 Exp。
暂时未发现较好的避免方法,唯有多测试。
parse 方法总结
所有节点类中都有 void parse() 用于解析当前节点,如果成功则将子树添加到自己名下,如果失败则作废自己并返回。针对 EBNF 则有以下总结:
|,该结点有多种可能,需要在最开始进行存档,每一个可能失败后读档,最后一个可能失败后作废并返回。以Decl → ConstDecl | VarDecl为例:
1 |
|
[...],方括号内包含可选项,出现 0 次或 1 次,需要在括号内内容开始读取前存档,失败则读档,成功则加入语法树。以VarDecl → [ 'static' ] BType ...为例:
1 |
|
{...},花括号内重复 0 次或多次,需要设置循环,每次循环开始时存档,读取失败则读档并退出循环,读取成功则加入语法树并继续循环。以Block → '{' { BlockItem } '}'为例:
1 |
|
- Title: 编译技术:语法分析
- Author: BaconToast
- Created at : 2025-11-14 22:41:54
- Updated at : 2025-11-18 13:26:32
- Link: https://bacontoast-pro.github.io/2025/11/14/compiler/parser/
- License: This work is licensed under CC BY-NC-SA 4.0.